
안녕하세요 Devloo 입니다 :). 이번 시간에는 Spring Boot 애플리케이션에서 캐싱을 효과적으로 구현하는 방법에 대해 자세히 알아보겠습니다. 캐싱을 제대로 활용하면 애플리케이션의 성능을 획기적으로 향상시킬 수 있으며, 이를 통해 사용자 경험도 크게 개선될 수 있습니다. 이 글을 통해 캐싱에 대한 깊이 있는 이해와 실전 적용 방법을 익히시길 바랍니다.

1. 최적의 성능을 위한 캐싱 대상 찾기
캐싱을 위해 가장 중요한 것은, 캐싱이 필요한 대상을 찾는 것입니다.
가장 먼저 떠오르는 것은 비용이 많이 들고 시간이 오래 걸리는 작업, 예를 들어 데이터베이스 쿼리, 웹 서비스 호출, 복잡한 계산 등이 있습니다.
이들은 분명 캐싱이 필요한 좋은 대상이지만, 캐싱이 필요한 대상의 일반적인 특징을 정의해두면 더 좋습니다. 이를 통해 우리 애플리케이션에서 캐싱이 필요한 부분을 쉽게 발견할 수 있습니다.
- 자주 접근하는 데이터: 자주 반복적으로 접근되는 데이터는 캐싱하기 좋은 대상입니다.
- 비용이 많이 드는 데이터 로드와 계산: 데이터를 가져오거나 처리하는 데 많은 시간이나 계산 자원이 필요한 경우.
- 정적 또는 거의 변하지 않는 데이터: 자주 변경되지 않는 데이터는 캐싱된 데이터가 오랜 기간 유효함을 보장합니다.
- 높은 읽기-쓰기 비율: 읽기 작업이 쓰기 작업보다 훨씬 더 자주 발생하는 데이터는 효과적으로 캐싱할 수 있습니다. 이는 캐시에서 빠르게 읽을 수 있는 이점이 업데이트와 관련된 비용을 넘어선다는 것을 의미합니다.
- 예측 가능한 패턴: 접근 패턴이 예측 가능한 데이터는 더 효율적인 캐시 관리를 가능하게 합니다.
이러한 특징을 통해 애플리케이션의 성능을 크게 향상시킬 수 있는 데이터를 효과적으로 찾고 캐싱을 할 수 있습니다.
2. 캐시 만료 (Cache Expiration)
적절한 만료 정책을 설정하면 캐시된 데이터가 유효하고 최신 상태를 유지하며 메모리 효율성을 보장할 수 있습니다. 이는 Spring Boot 애플리케이션의 성능과 일관성을 최적화하는 데 도움이 됩니다.
Spring Boot 애플리케이션에서 캐시 만료를 관리하기 위해 다음과 같은 접근 방식을 추천합니다:
삭제 정책 (Eviction Policies)
자주 쓰이는 삭제 정책에는 다음과 같은 것들이 있습니다:
- 최소 최근 사용 (LRU): 가장 최근에 접근한 항목을 먼저 삭제합니다.
- 최소 빈도 사용 (LFU): 가장 자주 접근되지 않은 항목을 먼저 삭제합니다.
- 선입선출 (FIFO): 가장 먼저 들어온 항목을 먼저 삭제합니다.
Spring Cache 추상화는 이러한 삭제 정책을 따로 지원하지 않지만, 캐시 제공자의 기능을 사용할 수 있습니다. 삭제 정책을 신중하게 선택하고 구성하면 캐싱 메커니즘이 애플리케이션의 성능과 자원 활용 목표에 맞게 효율적이고 효과적으로 유지될 수 있습니다.
시간 기반 만료 (Time-based Expiration)
TTL(유효 시간) 간격을 정의하여 일정 시간 후에 캐시 항목을 삭제하는 방법은 각 캐시 제공자마다 다릅니다. 예를 들어, Spring Boot 애플리케이션에서 Redis를 캐싱에 사용하는 경우, 다음과 같이 TTL을 지정할 수 있습니다:
spring.cache.redis.time-to-live=10m캐시 제공자가 TTL을 지원하지 않는 경우, @CacheEvict 어노테이션과 스케줄러를 사용하여 이를 구현할 수 있습니다:
@CacheEvict(value = "cache1", allEntries = true)
@Scheduled(fixedRateString = "${your.config.key.for.ttl.in.milli}")
public void emptyCache1() {
// 따로 코드 작성이 필요하지 않습니다.
}사용자 정의 삭제 정책 (Custom Eviction Policies)
특정 이벤트나 상황에 기반하여 개별 캐시 항목 또는 모든 항목에 대한 맞춤 만료 정책을 정의하면 캐시 오염을 방지하고 일관성을 유지할 수 있습니다. Spring Boot는 맞춤형 만료 정책을 지원하는 다양한 어노테이션을 제공합니다.
@CacheEvict: 캐시에서 하나 또는 모든 항목을 제거합니다.@CachePut: 새로운 값으로 항목을 업데이트합니다.
CacheManager: Spring의 CacheManager와 Cache 인터페이스를 사용하여 사용자 정의 삭제 정책을 구현할 수 있습니다. evict(), put(), clear()와 같은 메서드를 사용하여 이를 수행할 수 있습니다. getNativeCache() 메서드를 사용하여 기본 캐시 제공자에 접근하여 더 많은 기능을 사용할 수도 있습니다.
사용자 정의 삭제 정책에서 가장 중요한 것은 항목을 삭제할 올바른 위치와 조건을 찾는 것입니다.
3. 조건부 캐싱 (Conditional Caching)
조건부 캐싱은 삭제 정책과 함께 캐싱 전략을 최적화하는 데 중요한 역할을 합니다. 때로는 특정 엔터티의 모든 데이터를 캐시에 저장할 필요가 없습니다.
조건부 캐싱은 특정 기준을 충족하는 데이터만 캐시에 저장되도록 합니다.
이는 캐시 공간에서 불필요한 데이터를 방지하고 자원 활용을 최적화합니다.
@Cacheable과 @CachePut 어노테이션에는 캐싱 항목에 대한 조건을 정의할 수 있는 condition과 unless 속성이 있습니다:
- Condition: 데이터가 캐싱(또는 업데이트)되기 위해 참으로 평가되어야 하는 SpEL(Spring Expression Language) 표현식을 지정합니다.
- Unless: 데이터가 캐싱(또는 업데이트)되지 않기 위해 거짓으로 평가되어야 하는 SpEL 표현식을 지정합니다.
명확히 하기 위해 아래 코드를 확인하세요:
@Cacheable(value = "employeeByName", condition = "#result.size() > 10", unless = "#result.size() < 1000")
public List<Employee> employeesByName(String name) {
// 데이터를 검색하는 메서드 로직
return someEmployeeList;
}이 코드에서는 결과 리스트의 크기가 10보다 크고 1000보다 작은 경우에만 직원 목록이 캐시됩니다.
마지막으로, 이전 섹션과 마찬가지로 CacheManager와 Cache 인터페이스를 사용하여 조건부 캐싱을 프로그래밍 방식으로 구현할 수도 있습니다. 이를 통해 캐싱 동작에 대한 유연성과 제어를 더욱 강화할 수 있습니다.
4. 분산 캐시 vs 로컬 캐시
캐싱에 대해 이야기할 때, 우리는 보통 Redis, Memcached, Hazelcast와 같은 분산 캐시를 떠올립니다. 마이크로서비스 아키텍처의 인기가 높아지면서 로컬 캐싱도 애플리케이션 성능을 개선하는 데 큰 역할을 하고 있습니다.
로컬 캐시와 분산 캐시의 차이를 이해하면 Spring Boot 애플리케이션에서 적절한 캐싱 전략을 선택하는 데 도움이 됩니다.
각 유형은 장단점이 있으며, 애플리케이션의 필요에 따라 고려해야 합니다.
로컬 캐시란 무엇인가요?
로컬 캐시는 애플리케이션이 실행되는 동일한 머신이나 인스턴스의 메모리에 데이터를 저장하는 캐싱 메커니즘입니다. 잘 알려진 로컬 캐싱 라이브러리로는 Ehcache, Caffeine, Guava Cache가 있습니다.
로컬 캐시는 원격 데이터 검색과 관련된 네트워크 지연 시간과 오버헤드를 피하기 때문에 캐시된 데이터에 매우 빠르게 접근할 수 있습니다. 일반적으로 로컬 캐시는 설정 및 관리가 분산 캐시보다 쉽고 추가 인프라가 필요하지 않습니다.
로컬 캐시와 분산 캐시는 언제 사용해야 하나요?
로컬 캐시는 데이터 세트가 작고 단일 머신의 메모리에 충분히 들어갈 수 있는 작은 애플리케이션이나 마이크로서비스에 적합합니다. 또한 낮은 지연 시간이 중요하고 인스턴스 간 데이터 일관성이 큰 문제가 되지 않는 상황에 적합합니다.
반면, 분산 캐시 시스템은 대규모 데이터 캐싱이 필요한 대형 애플리케이션에 적합하며, 이 경우 확장성, 장애 허용성 및 여러 인스턴스 간 데이터 일관성이 중요합니다.
Spring Boot에서 로컬 캐시 구현
Spring Boot는 Ehcache, Caffeine, ConcurrentHashMap과 같은 다양한 인메모리 캐시 제공자를 통해 로컬 캐싱을 지원합니다. 필요한 것은 의존성을 추가하고 Spring Boot 애플리케이션에서 캐싱을 활성화하는 것뿐입니다. 예를 들어, Caffeine을 사용하여 로컬 캐싱을 구현하려면 다음 의존성을 추가해야 합니다:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-cache</artifactId>
</dependency>
<dependency>
<groupId>com.github.ben-manes.caffeine</groupId>
<artifactId>caffeine</artifactId>
</dependency>그런 다음 @EnableCaching 애너테이션을 사용하여 캐싱을 활성화합니다:
@SpringBootApplication
@EnableCaching
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}일반적인 Spring Cache 구성 외에도, Caffeine 캐시를 다음과 같이 특정 구성으로 설정할 수 있습니다:
spring:
cache:
caffeine:
spec: maximumSize=500,expireAfterAccess=10m5. 사용자 정의 키 (Custom Key) 생성 전략
Spring Cache 어노테이션의 기본 키 생성 알고리즘은 보통 아래와 같이 작동합니다:
파라미터가 없으면 0을 반환합니다.
파라미터가 하나만 있으면 해당 인스턴스를 반환합니다.
파라미터가 여러 개면 모든 파라미터의 해시를 계산하여 키를 반환합니다.
이 접근 방식은 객체에 자연 키가 있고
hashCode()메서드가 이를 반영하는 한 잘 작동합니다.
하지만 아래와 같은 상황에선 기본 키 생성 전략이 맞지 않습니다:
- 의미 있는 키(Meaningful Key)가 필요한 경우
- 동일한 유형의 여러 파라미터가 있는 메서드
- Optional 또는 NULL 파라미터가 있는 메서드
- 키를 고유하게 만들기 위해 locale, tenet ID, 사용자 역할과 같은 컨텍스트 데이터를 포함해야 하는 경우
Spring Cache는 사용자 정의 키 생성 전략을 정의하는 두 가지 접근 방식을 제공합니다:
- SpEL (Spring Expression Language) 표현식을 사용하여
KEY속성에 새로운 키를 생성하도록 지정합니다:
@CachePut(value = "phonebook", key = "#phoneNumber.name")
PhoneNumber create(PhoneNumber phoneNumber) {
return phonebookRepository.insert(phoneNumber);
}KeyGenerator인터페이스를 구현한 빈을 정의하고 이를keyGenerator속성에 지정합니다:
@Component("customKeyGenerator")
public class CustomKeyGenerator implements KeyGenerator {
@Override
public Object generate(Object target, Method method, Object... params) {
return "UNIQUE_KEY";
}
}
@CachePut(value = "phonebook", keyGenerator = "customKeyGenerator")
PhoneNumber create(PhoneNumber phoneNumber) {
return phonebookRepository.insert(phoneNumber);
}사용자 정의 키 생성 전략을 사용하면 애플리케이션의 캐시 효율성과 효과를 크게 향상시킬 수 있습니다. 잘 설계된 키 생성 전략은 캐시 항목이 올바르게 고유하게 식별되도록 하여 캐시 미스를 최소화하고 캐시 히트를 최대화합니다.
6. 비동기(Async) 캐시
여러분이 이미 알고 있듯이, Spring Cache 추상화 API는 블로킹이며 동기 방식입니다. 만약 WebFlux 스택을 사용하면서 @Cacheable이나 @CachePut 같은 Spring Cache 어노테이션을 사용한다면, 이는 Reactor Wrapper 객체(Mono 또는 Flux)를 캐시하게 됩니다. 이 경우, 다음 세 가지 접근 방식이 있습니다:
- 리액터 타입에 대해
cache()메서드를 호출하고 이 메서드에 Spring Cache 어노테이션을 적용합니다. - 기본 캐시 제공자가 제공하는 비동기 API를 사용하고, 프로그래밍 방식으로 캐싱을 처리합니다.
- 캐시 API 주변에 비동기 래퍼를 구현하고, 캐시 제공자가 지원하지 않는 경우 비동기로 만듭니다.
그러나 Spring Framework 6.2 출시 이후, 캐시 제공자가 WebFlux 프로젝트를 위한 비동기 캐시를 지원하는 경우(예: Caffeine Cache):
Spring의 선언적 캐싱 인프라는 리액티브 메서드 시그니처(예: Reactor Mono 또는 Flux를 반환하는 메서드)를 감지하고, 반환된 Reactive Streams Publisher 인스턴스를 캐시하려고 시도하는 대신 해당 메서드가 생성한 값을 비동기적으로 캐싱하기 위해 특별하게 처리합니다. 이를 위해서는
CaffeineCacheManager를setAsyncCacheMode(true)로 설정하는 등 대상 캐시 제공자에서 지원이 필요합니다.
설정은 매우 간단합니다:
@Configuration
@EnableCaching
public class CacheConfig {
@Bean
public CacheManager cacheManager() {
final CaffeineCacheManager cacheManager = new CaffeineCacheManager();
cacheManager.setCaffeine(buildCaffeineCache());
cacheManager.setAsyncCacheMode(true); // <-- Async 캐시 모드 활성화
return cacheManager;
}
}7. 캐시 모니터링을 통한 병목 지점 찾기
애플리케이션의 캐싱 전략을 최적화하고 병목 현상을 발견하려면 캐시 메트릭(Cache Metrics)를 모니터링하는 것이 중요합니다.
모니터링해야 할 가장 중요한 메트릭은 아래와 같습니다:
- 캐시 적중률(Cache Hit Rate): 총 캐시 요청 대비 캐시 히트 비율로, 효과적인 캐싱을 나타냅니다. 낮은 히트율은 캐시가 효과적으로 활용되지 못하고 있음을 의미합니다.
- 캐시 미스율(Cache Miss Rate): 총 캐시 요청 대비 캐시 미스 비율로, 캐시가 요청된 데이터를 자주 제공하지 못하는 경우를 나타냅니다. 이는 캐시 크기가 충분하지 않거나 키 관리가 부실할 때 발생할 수 있습니다.
- 캐시 제거율(Cache Eviction Rate): 캐시에서 항목이 제거되는 빈도입니다. 제거율이 높으면 캐시 크기가 너무 작거나 제거 정책이 접근 패턴에 적합하지 않음을 나타냅니다.
- 메모리 사용량(Memory Usage): 캐시에 사용되는 메모리의 양입니다.
- 지연 시간(Latency): 캐시에서 데이터를 검색하는 데 걸리는 시간입니다.
- 오류율(Error Rates): 초당 요청 수와 같은 캐시 서버의 부하와 관련된 메트릭입니다.
Spring Boot에서 캐시 메트릭 모니터링 방법
Spring Boot Actuator는 시작 시 모든 사용 가능한 캐시 인스턴스에 대해 Micrometer를 자동으로 구성합니다. 시작 후 동적으로 또는 프로그래밍 방식으로 생성된 캐시는 별도로 등록해야 합니다. 지원되는 캐시 제공자를 확인하려면 이 링크에서 확인하세요.
먼저, Actuator와 Micrometer 의존성을 추가해야 합니다:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-registry-prometheus</artifactId>
</dependency>그런 다음 Actuator 엔드포인트를 활성화합니다:
management.endpoints.web.exposure.include=*이제 이 엔드포인트 /actuator/caches를 사용하여 구성된 캐시 목록을 볼 수 있으며, 캐시 메트릭스에 대해서는 다음을 사용할 수 있습니다:
/actuator/metrics/cache.gets/actuator/metrics/cache.puts/actuator/metrics/cache.evictions/actuator/metrics/cache.removals
Digma로 캐싱 최적화를 하는 방법
Digma는 런타임 동작에 대한 통찰력을 제공하여 팀이 애플리케이션을 이해하고 최적화할 수 있도록 돕는 관측성 플랫폼(Observerbility Platform) 입니다. 캐싱 최적화와 관련하여, Digma는 상세한 분석, 모니터링, 그리고 실행 가능한 권장 사항을 제공함으로써 중요한 역할을 할 수 있습니다.
인사이트: Digma는 애플리케이션의 메트릭을 실시간으로 모니터링하고, 캐시 미스와 같은 캐싱 관련 문제를 신속하게 발견합니다.
상세한 메트릭 및 분석: Digma는 상세 메트릭을 수집하고 시각화하여, IDE 내에서 개발 중 애플리케이션 동작을 모니터링할 수 있는 종합적인 뷰를 제공합니다.
개발 워크플로와의 통합: Digma는 기존의 개발 및 CI/CD 워크플로우와 통합되어, 정기적인 개발 작업에 캐시 최적화를 쉽게 포함할 수 있도록 합니다.
다음은 Digma가 실제로 캐싱 최적화를 도와주는 두 가지 예를 소개합니다:
- 캐싱 후보 식별: 이 기능은 캐싱이 애플리케이션 내에서 요청 처리에 어떻게 영향을 미치는지에 대한 종합적인 뷰를 제공합니다. 캐싱으로 이점을 얻을 수 있는 요청(Request)을 구체적으로 찾아줍니다.
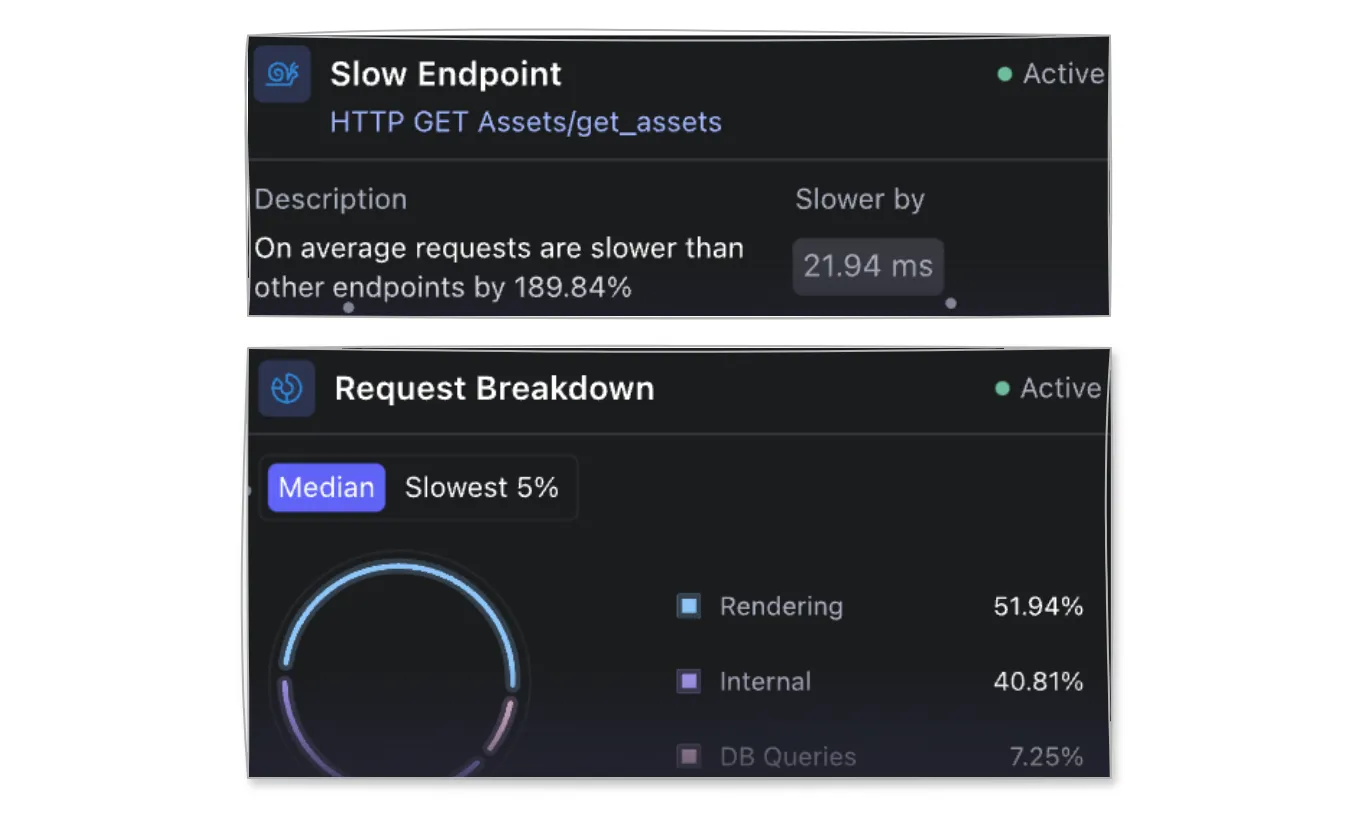
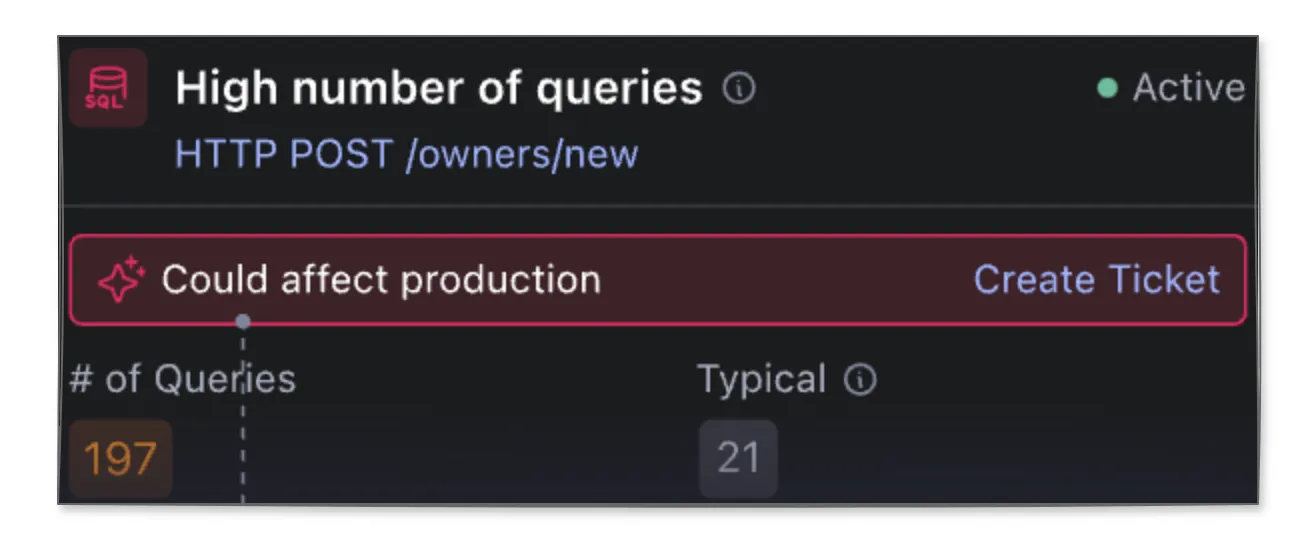
- 비효율적인 쿼리 찾기: 이 기능은 애플리케이션 내에서 시간이 많이 소요되고 캐싱의 이점을 크게 볼 수 있는 비효율적인 데이터베이스 쿼리를 감지하는 데 중점을 둡니다. 예를 들어, Digma가 제공하는 High number of queries 기능은 현재 엔드포인트가 비정상적인 수의 DB 쿼리를 호출하고 있음을 나타냅니다. 이는 일반적으로 캐싱을 하거나 더 최적화된 쿼리를 통해 해결할 수 있습니다. 또 다른 예로, Query Optimization Suggested insight 기능은 동일한 DB에서 실행되는 동일 유형의 다른 쿼리보다 상대적으로 느린 쿼리를 발견합니다. 이 경우 해당 쿼리를 최적화하거나 캐시를 사용할 수 있습니다.
Digma의 분석 기능을 활용함으로써, 캐싱 성능에 대한 깊은 통찰력을 얻고, 문제를 신속하게 찾고 해결하며, 캐싱 전략을 지속적으로 튜닝할 수 있습니다.
결론
제가 작성한 다른 글 “Spring Boot 성능을 극대화하는 10가지 방법“에서는 캐싱을 Spring Boot 애플리케이션 성능 향상의 중요한 방법으로 소개했습니다. 이번 글에서는 Spring Boot 애플리케이션에서 캐싱을 최적화하는 7가지 기술을 배웠습니다.
캐싱 최적화는 애플리케이션 성능과 확장성을 직접적으로 향상시키기 때문에 매우 중요합니다. 이를 통해 백엔드 시스템의 부하를 줄이고 데이터 검색 속도를 높일 수 있습니다. 효율적인 캐싱 전략은 지연 시간을 최소화하고, 더 빠른 응답 시간을 보장하며, 전체적인 사용자 경험을 개선합니다.
지금까지 Spring Boot 캐싱(Caching) 최적화의 7가지 방법을 알아보았습니다.
끝까지 읽어주셔서 정말 감사합니다. 혹시 궁금하신 사항이 있으시면 댓글 남겨주세요 🙂



 Spring Boot 통일된 응답과 예외 처리
Spring Boot 통일된 응답과 예외 처리